

What is Quality of Service (QoS)? Write a difference between policing and shaping.
Quality of service (QoS) is the use of mechanisms or technologies that work on a network to control traffic and ensure the performance of critical applications with limited network capacity. It enables organizations to adjust their overall network traffic by prioritizing specific high-performance applications.
QoS is typically applied to networks that carry traffic for resource-intensive systems. Common services for which it is required include internet protocol television (IPTV), online gaming, streaming media, videoconferencing, video on demand (VOD), and Voice over IP (VoIP).
Using QoS in networking, organizations have the ability to optimize the performance of multiple applications on their network and gain visibility into the bit rate, delay, jitter, and packet rate of their network. This ensures they can engineer the traffic on their network and change the way that packets are routed to the internet or other networks to avoid transmission delay. This also ensures that the organization achieves the expected service quality for applications and delivers expected user experiences.
The difference Between policing and shaping are:
What is syslog? Explain the various levels of a syslog message.
Syslog is a Message Logging Standard by which almost any device or application can send data about status, events, diagnostics, and more. Syslog messages have a built-in severity level, facilitating anything from level 0, an Emergency, to level 5, a Warning, and then on to level 6 and level 7, which are Informational and Debugging, respectively.One of the most notable useful aspects of Syslog, though sometimes it can also be a hindrance, is how open-ended it is.Explanation of the severity Levels:
What are the different OSPF network types and give an example for each?
OSPF addresses three classes of network (as listed in section 1.2 of RFC 2328): point-to-point, broadcast, and non-broadcast.
Point-to-Point
This is by far the simplest network type, and serves as a convenient anchor from which to advance the discussion. A point-to-point network is, as its name aptly describes, a link between exactly two points (or routers). A packet sent from on of the routers will always have exactly one recipient on the local link.
Broadcast
Obviously, point-to-point links don't scale well. A much more efficient manner of connecting a large number of devices is to implement a multiaccess segment; that is, a segment which can be accessed by multiple end points. An Ethernet segment is an example of such a network.

Ethernet networks support broadcasts; a single packet transmitted by a device can be multiplied by the medium (in this case an Ethernet switch) so that every other end point receives a copy. This is advantageous not only in bandwidth savings, but also in facilitating automatic neighbor discovery.
In the example pictured above, R1 can multicast (a broadcast intended only for certain recipients) an OSPF hello message to the link, knowing that all other OSPF routers connected to the link will receive it and reply with their own multicast message. Consequently, neighbors can quickly identify each other and form adjacencies without knowing addresses beforehand. Isn't that convenient?
OSPF routers on a multiaccess segment will elect a designated router (DR) and backup designated router (BDR) with which all non-designated routers will form an adjacency. This is to ensure that the number of adjacencies maintained does not grow too large; a segment containing ten routers would require 45 adjacencies to form a mesh, but only 17 when a DR and BDR are in place.
Non-Broadcast
Unfortunately, not all multiaccess technologies support broadcast transmissions. Frame relay and ATM are probably the most common examples of non-broadcast transport, requiring individual permanent virtual circuits (PVCs) to be configured between end points.
Notice in the frame relay topology pictured above, R1 must craft and transmit an individual packet for every destination he wants to reach. Aside from being horribly inefficient with regard to bandwidth, this limitation requires the router to know the addresses of his neighbors before he can communicate to them.
OSPF can operate in one of two modes across a non-broadcast network: non-broadcast multi-access (NBMA) or point-to-multipoint. Each of these topologies tackles the absence of broadcast capability from a different direction.
Non-Broadcast Multi-Access (NBMA)
An NBMA segment emulates the function of a broadcast network. Every router on the segment must be configured with the IP address of each of its neighbors. OSPF hello packets are then individually transmitted as unicast packets to each adjacent neighbor.
As in a true broadcast network, a DR and BDR are elected to limit the number of adjacencies formed.
Point-to-Multipoint
A point-to-multipoint configuration approaches the non-broadcast limitation in a different manner. Rather than trying to emulate broadcast capability, it seeks to organize the PVCs into a collection of point-to-point networks. Hello packets must still be replicated and transmitted individually to each neighbor, but the multipoint approach offers two distinct advantages: no DR/BDR is needed, and the emulated point-to-point links can occupy a common subnet.
All routers attached to a non-broadcast network must be manually configured to recognize it as a point-to-multipoint segment:
Router(config-if)# ip ospf network point-to-multipoint [non-broadcast]
The non-broadcast parameter can be appended to the OSPF network type to force unicasting of packets rather than relying on multicast. This might be necessary when dynamic circuits are in use.
What is OSPF and what are the different OSPF states?
Open Shortest Path First (OSPF) is a link-state routing protocol that is used to find the best path between the source and the destination router using its own Shortest Path First). OSPF is developed by Internet Engineering Task Force (IETF) as one of the Interior Gateway Protocol (IGP), i.e, the protocol which aims at moving the packet within a large autonomous system or routing domain. It is a network layer protocol which works on protocol number 89 and uses AD value 110. OSPF uses multicast address 224.0.0.5 for normal communication and 224.0.0.6 for update to designated router(DR)/Backup Designated Router (BDR).
DOWN STATE
The Down State is the first OSPF neighbor state and means no Hello packets have been received from a neighbor. In an already established OSPF adjacency, an OSPF state will transition from a FULL or 2-Way State to the Down State when the router Dead Interval Timer expires (4 x Hello Interval timer), which means OSPF has lost communication with its neighbor and is now considered non-reachable or dead.
This is a special state used only for manually configured neighbors in a Non-Broadcast MultiAccess (NBMA) network, it indicates that the router is sending Hello packets to its neighbor in a Non-Broadcast MultiAccess (NBMA) environment via unicast but no reply is received within the Dead Interval (4 x Hello Interval).
An example of an NBMA network is a Frame Relay network where there are no intrinsic broadcast and multicast capabilities.
2-WAY STATE
This state indicates that a Hello packet was received from a neighbor router but the receiving Router’s ID wasn’t listed in the Hello packet. When a router receives a Hello packet from a neighbor, it should list the sender's Router ID as an acknowledgment that it previously received a valid Hello packet.
This state describes the Bi-Directional communication state, Bi- Directional means that each router has received the other’s Hello packet and that each router can see its own Router ID included within the Hello packet’s neighbor field.
On broadcast media (e.g LAN) and Non-Broadcast MultiAccess (NBMA) networks (e.g Frame Relay, ATM, X.25), a router becomes full state (analyzed below) only with the Designated Router (DR) and the Backup Designated Router (BDR). It will, however, stay in the 2-way state with all other neighbors.
When the 2-Way state is complete, the DR and DBR routers are elected, considering they are on a broadcast or NBMA network.
EXSTART STATE
This state specifies that DR and BDR have been elected and master-slave relation is determined. An initial sequence number for adjacency formation is also selected. The router with the highest router ID becomes the master and begins to exchange Link State data. Only the Master router is able to increment the sequence number.
EXCHANGE STATE
In this state, OSPF routers exchange DataBase Descriptor (DBD) packets. These contain Link State Advertisement (LSA) headers describing the content of the entire Link State Database (LSD). The contents of the DataBase Descriptor (DBD) received by the router are compared with its own Link State Database (LSD) to check if changes or additional link-state information is available from its neighbor.
LOADING STATE
In this state, routers exchange full Link State information based on DataBase Descriptor (DBD) provided by neighbors, the OSPF router sends Link State Request (LSR) and receives Link State Update (LSU) containing all Link State Advertisements (LSAs).
Link State Updates (LSU) actually act as an envelope that contains all the Link State Advertisements (LSAs) – that have been sent to neighbors with new changes or new networks learned.
FULL STATE
Full state is the normal operating state of OSPF that indicates everything is functioning normally. In this state, routers are fully adjacent with each other and all the router and network Link State Advertisements (LSAs) are exchanged and the routers' databases are fully synchronized.
For Broadcast and NBMA media, routers will achieve the Full State with their DR and BDR router only, while for Point-to-point and Point-to-multipoint networks a router should be in the Full State with every neighboring router.
This article analyzed the states OSPF routers go through during OSPF neighbor discovery and adjacency process. We examined in detail each OSPF State including: Down state, Attempt state, Init state, 2-way state, Exstart state, Exchange state, Loading state and Full state.
.
What is network security? Explain different types of attacks in network security?
Network security is a broad term that covers a multitude of technologies, devices and processes. In its simplest term, it is a set of rules and configurations designed to protect the integrity, confidentiality and accessibility of computer networks and data using both software and hardware technologies. Every organization, regardless of size, industry or infrastructure, requires a degree of network security solutions in place to protect it from the ever-growing landscape of cyber threats in the wild today.
Today's network architecture is complex and is faced with a threat environment that is always changing and attackers that are always trying to find and exploit vulnerabilities. These vulnerabilities can exist in a broad number of areas, including devices, data, applications, users and locations. For this reason, there are many network security management tools and applications in use today that address individual threats and exploits and also regulatory non-compliance. When just a few minutes of downtime can cause widespread disruption and massive damage to an organization's bottom line and reputation, it is essential that these protection measures are in place.
Network attacks occur in various forms. Enterprises need to ensure that they maintain the highest cybersecurity standards, network security policies, and staff training to safeguard their assets against increasingly sophisticated cyber threats.
DDoS
DDoS (distributed denial of service) attacks involve deploying sprawling networks of botnets — malware-compromised devices linked to the internet. These bombard and overwhelm enterprise servers with high volumes of fraudulent traffic. Malicious attackers may target time-sensitive data, such as that belonging to healthcare institutions, interrupting access to vital patient database records.
Man-in-the-middle Attacks
Man-in-the-middle (MITM) network attacks occur when malicious parties intercept traffic conveyed between networks and external data sources or within a network. In most cases, hackers achieve man-in-the-middle attacks via weak security protocols. These enable hackers to convey themselves as a relay or proxy account and manipulate data in real-time transactions.
Unauthorized Access
Unauthorized access refers to network attacks where malicious parties gain access to enterprise assets without seeking permission. Such incidences may occur due to weak account password protection, unencrypted networks, insider threats that abuse role privileges, and the exploitation of inactive roles with administrator rights.
Organizations should prioritize and maintain the least privilege principle to avoid the risks of privilege escalation and unauthorized access.
SQL Injection
Unmoderated user data inputs could place organizational networks at risk of SQL injection attacks. Under the network attack method, external parties manipulate forms by submitting malicious codes in place of expected data values. They compromise the network and access sensitive data such as user passwords.
There are various SQL injection types, such as examining databases to retrieve details on their version and structure and subverting logic on the application layer, disrupting its logic sequences and function.
Network users can reduce the risks of SQL injection attacks by implementing parameterized queries/prepared statements, which helps verify untrusted data inputs.
What are the characteristics of ospf? Describe the five OSPF packet types?
OSPF is a link-state protocol that has the following characteristics for deployment in enterprise networks:
■ Fast convergence: OSPF achieves fast convergence times using triggered link-state updates that include one or more link-state advertisements (LSA). LSAs describe the state of links on specific routers and are propagated unchanged within an area. Therefore, all routers in the same area have identical topology tables; each router has a complete view of all links and devices in the area. Depending on their type, LSAs are usually changed by ABRs when they cross into another area.
Very good scalability: OSPF's multiple area structure provides good scalability. However, OSPF's strict area implementation rules require proper design to support other scalability features such as manual summarization of routes on ABRs and ASBRs, stub areas, totally stubby areas, and not-so-stubby areas (NSSA). The stub, totally stubby, and NSSA features for nonbackbone areas decrease the amount of LSA traffic from the backbone (area 0) into nonbackbone areas (and they are described further in the following sidebar). This allows low-end routers to run in the network's peripheral areas, because fewer LSAs mean smaller OSPF topology tables, less OSPF memory usage, and lower CPU usage in stub area routers.
Reduced bandwidth usage: Along with the area structure, the use of triggered (not periodic) updates and manual summarization reduces the bandwidth used by OSPF by limiting the volume of link-state update propagation. Recall, though, that OSPF does send updates every 30 minutes.
VLSM support: Because OSPF is a classless routing protocol, it supports VLSM to achieve better use of IP address space.
The following packet types are supported for i5/OS in an OSPF environment
Hello packet
This packet is sent by the OMPROUTED server to discover OSPF neighbor routers and to establish bidirectional communications with them.
When several systems or routers that run OSPF have interfaces attached to a common network, the Hello protocol determines the designated router (DR). The DR is adjacent to all routers on the network, and its role is to generate and flood the LSAs on behalf of the network. In a broadcast network, such as Ethernet, having a DR reduces the amount of router protocol traffic that is generated.
The DR is also responsible for maintaining the network topology database that is replicated at all other routers that are within the same OSPF area on the network.
The concept of a DR does not exist for point-to-point connections.
Database description packet
Once the Hello packets are exchanged and two-way communications are established, the i5/OS and other area routers are neighbors. At this point the OMPROUTED server knows with which neighbors it must establish adjacencies and then starts forming OSPF adjacencies. Bringing up an adjacency is the important OSPF protocol function for synchronizing databases between routers. The database description packets are sent using the exchange database protocol. The exchange database protocol exchanges a description of the link-state databases between adjacent partners, using the database description packet.
Link-state update packet
Until the OMPROUTED databases are fully synchronized, they request and exchange more information from adjacent routers using link-state request and link-state updates packets.
The router or i5/OS whose router identifier is numerically higher, assumes the primary role and the other assumes the secondary role. The primary router sends its database descriptions, one at a time. The secondary router acknowledges each one and includes in the acknowledgement its own database descriptions. The records are compared according to the type, advertising router, and link-state ID. A sequence number in the record determines whether the record is newer or older. If the new description indicates that this record is newer than the recipient already has in its database, this description is saved.
Link-state request packet
After all descriptions are received, the neighbors send out database requests for more complete information about the records that were requested. These requests are followed with a flood of Link-state updates containing the requested information. Each link-state update packet is acknowledged, either explicitly with a link-state acknowledgment packet or implicitly in the link-state packets. The routers are fully adjacent when the link-state databases are fully synchronized.
OSPF adjacency states are Down, Init, Attempt, 2-way, Exstart, Exchange, Loading, and Full. On i5/OS, 2-way is represented by *WAY2 means that the router is fully adjacent only with the DR or the backup designated router (BDR). When the adjacency state is *FULL, this means that many neighbor states might be *WAY2 and therefore an individual router might know about a neighbor but not be fully adjacent to it.
If the database synchronization process is too long, consider setting the database exchange timeout value higher than the default value that is specified by the inactive router interval. Set the database exchange timeout value when adding or changing an interface with the ADDOSPFIFC or CHGOSPFIFC command. If the database exchange timeout is set higher than the default time, the following occurs:
The database synchronization fails due to insufficient time.
The neighbor process never stabilizes beyond neighbor State of *WAY2.
Link-state acknowledgment packet
Each newly received LSA must be acknowledged by its recipient to verify its delivery. This is done by sending a link-state acknowledgment packet, which contains one or more acknowledgements. An acknowledgment packet is either sent immediately or delayed, based on a specified time interval.
What is RIP? Explain how RIP and OSPF calculate metric value?
RIP stands for Routing Information Protocol. RIP is an intra-domain routing protocol used within an autonomous system. Here, intra-domain means routing the packets in a defined domain, for example, web browsing within an institutional area. To understand the RIP protocol, our main focus is to know the structure of the packet, how many fields it contains, and how these fields determine the routing table.Routing Information Protocol (RIP) is a dynamic routing protocol that uses hop count as a routing metric to find the best path between the source and the destination network. It is a distance-vector routing protocol that has an AD value of 120 and works on the Network layer of the OSI model. RIP uses port number 520.
Explain is static routing and its type with syntax.
Static routing is a type of network routing technique. Static routing is not a routing protocol; instead, it is the manual configuration and selection of a network route, usually managed by the network administrator. It is employed in scenarios where the network parameters and environment are expected to remain constant.
Static routing is only optimal in a few situations. Network degradation, latency and congestion are inevitable consequences of the non-flexible nature of static routing because there is no adjustment when the primary route is unavailable.
Static Route Applications (2.1.2.1)
Static routes are most often used to connect to a specific network or to provide a Gateway of Last Resort for a stub network. They can also be used to:
Reduce the number of routes advertised by summarizing several contiguous networks as one static route
Create a backup route in case a primary route link fails
The following types of IPv4 and IPv6 static routes will be discussed:
Standard static route
Default static route
Summary static route
Floating static route
Standard Static Route (2.1.2.2)
Both IPv4 and IPv6 support the configuration of static routes. Static routes are useful when connecting to a specific remote network.
Figure 2-4 shows that R2 can be configured with a static route to reach the stub network 172.16.3.0/24.
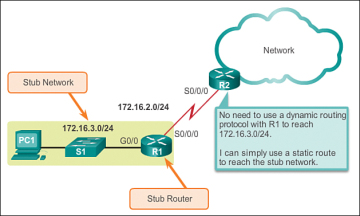
Figure 2-4 Connecting to a Stub Network
NOTE
The example is highlighting a stub network, but in fact, a static route can be used to connect to any network.
Default Static Route (2.1.2.3)
A default static route is a route that matches all packets. A default route identifies the gateway IP address to which the router sends all IP packets that it does not have a learned or static route for. A default static route is simply a static route with 0.0.0.0/0 as the destination IPv4 address. Configuring a default static route creates a Gateway of Last Resort.
NOTE
All routes that identify a specific destination with a larger subnet mask take precedence over the default route.
Default static routes are used:
When no other routes in the routing table match the packet destination IP address. In other words, when a more specific match does not exist. A common use is when connecting a company’s edge router to the ISP network.
When a router has only one other router to which it is connected. This condition is known as a stub router.
Refer to Figure 2-5 for a sample scenario of implementing default static routing.
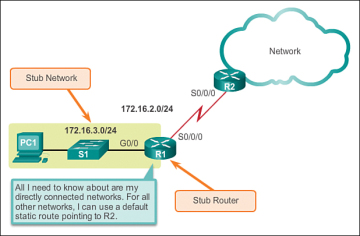
Figure 2-5 Connecting to a Stub Router
Summary Static Route (2.1.2.4)
To reduce the number of routing table entries, multiple static routes can be summarized into a single summary static route if:
The destination networks are contiguous and can be summarized into a single network address.
The multiple static routes all use the same exit interface or next-hop IP address.
In Figure 2-6, R1 would require four separate static routes to reach the 172.20.0.0/16 to 172.23.0.0/16 networks. Instead, one summary static route can be configured and still provide connectivity to those networks.

Figure 2-6 Using One Summary Static Route
Floating Static Route (2.1.2.5)
Another type of static route is a floating static route. Floating static routes are static routes that are used to provide a backup path to a primary static or dynamic route, in the event of a link failure. The floating static route is only used when the primary route is not available.
To accomplish this, the floating static route is configured with a higher administrative distance than the primary route. Recall that the administrative distance represents the trustworthiness of a route. If multiple paths to the destination exist, the router will choose the path with the lowest administrative distance.
For example, assume that an administrator wants to create a floating static route as a backup to an EIGRP-learned route. The floating static route must be configured with a higher administrative distance than EIGRP. EIGRP has an administrative distance of 90. If the floating static route is configured with an administrative distance of 95, the dynamic route learned through EIGRP is preferred to the floating static route. If the EIGRP-learned route is lost, the floating static route is used in its place.
In Figure 2-7, the Branch router typically forwards all traffic to the HQ router over the private WAN link. In this example, the routers exchange route information using EIGRP. A floating static route, with an administrative distance of 91 or higher, could be configured to serve as a backup route. If the private WAN link fails and the EIGRP route disappears from the routing table, the router selects the floating static route as the best path to reach the HQ LAN.

Syntax used
ip route is used to create a static route.
destination_network is the network in which you are trying to reach.
subnet_mask is used on the network.
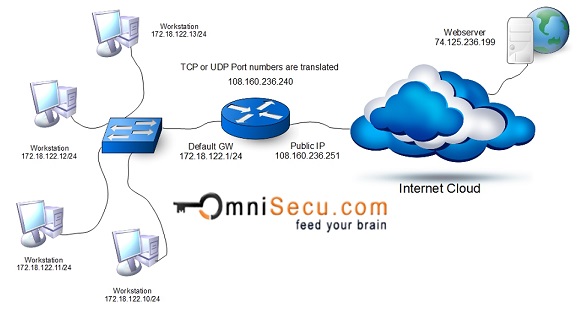
next-hop_address is the ip address of a router’s interface that is a directly connected network. It will receive the packet from the router and forward it to the remote network.Static NAT (Network Address Translation) - Static NAT (Network Address Translation) is one-to-one mapping of a private IP address to a public IP address. Static NAT (Network Address Translation) is useful when a network device inside a private network needs to be accessible from internet.

Dynamic NAT (Network Address Translation) - Dynamic NAT can be defined as mapping of a private IP address to a public IP address from a group of public IP addresses called as NAT pool. Dynamic NAT establishes a one-to-one mapping between a private IP address to a public IP address. Here the public IP address is taken from the pool of IP addresses configured on the end NAT router. The public to private mapping may vary based on the available public IP address in NAT pool.

PAT (Port Address Translation) - Port Address Translation (PAT) is another type of dynamic NAT which can map multiple private IP addresses to a single public IP address by using a technology known as Port Address Translation.
Here when a client from inside network communicate to a host in the internet, the router changes the source port (TCP or UDP) number with another port number. These port mappings are kept in a table. When the router receive from internet, it will refer the table which keep the port mappings and forward the data packet to the original sender.
exit interface is used in place of the next-hop address (if required).
The OSPF Router ID is used to provide a unique identity to the OSPF Router. OSPF Router ID is an IPv4 address (32-bit binary number) assigned to each router running the OSPF protocol. If there is no Loopback Interfaces configured, the highest IP address on its active interfaces is selected as the OSPF Router ID.
Each Router in an OSPF network needs a unique OSPF Router ID. The OSPF Router ID is used to provide a unique identity to the OSPF Router.
OSPF Router ID is an IPv4 address (32-bit binary number) assigned to each router running the OSPF protocol.
OSPF Router ID should not be changed after the OSPF process has been started and the ospf neighborships are established. If you change the OSPF router ID, we need to either reload the IOS or use "clear ip ospf process" command, for OSPF Router ID change to take effect. Reloading the IOS or using "clear ip ospf process" commad can cause temporary network outage.
OSPF Router ID selection algorithm works as below.
• Any manually configured OSPF Router ID in OSPF Process is selected as the OSPF Router ID.
• If there is no OSPF Router ID configured, the highest IP address on any of the Routers Loopback Interfaces is selected as the OSPF Router ID.
• If there is no Loopback Interfaces configured, the highest IP address on its active interfaces is selected as the OSPF Router ID.
To configure OSPF Route ID in OSPF Process, follow these steps.
omnisecu.com.R1>enable
omnisecu.com.R1#configure terminal
omnisecu.com.R1(config)#router ospf 100
omnisecu.com.R1(config-router)#router-id 1.1.1.1
omnisecu.com.R1(config-router)#exit
omnisecu.com.R1(config)#exit
omnisecu.com.R1#
A default gateway is a node that enables a connection between networks in order to allow machines on other networks to communicate. The 'default' part of the terminology relates to the fact it is often the first and default route taken.
A default gateway is most commonly used for webpage access; a request is sent through the gateway before it actually gets on to the internet. Another use cases include connecting multiple devices to a single subnet. In that scenario, the default gateway acts as an intermediary.
Next hop is a routing term that refers to the next closest router a packet can go through. The next hop is among the series of routers that are connected together in a network and is the next possible destination for a data packet. More specifically, next hop is an IP address entry in a router's routing table, which specifies the next closest/most optimal router in its routing path. Every single router maintains its routing table with a next hop address, which is calculated based on the routing protocol used and its associated metric.
Administrative distance is the feature that routers use in order to select the best path when there are two or more different routes to the same destination from two different routing protocols. Administrative distance defines the reliability of a routing protocol. Each routing protocol is prioritized in order of most to least reliable (believable) with the help of an administrative distance value.
IPsec is a group of protocols that are used together to set up encrypted connections between devices. It helps keep data sent over public networks secure. IPsec is often used to set up VPNs, and it works by encrypting IP packets, along with authenticating the source where the packets come from.
Within the term "IPsec," "IP" stands for "Internet Protocol" and "sec" for "secure." The Internet Protocol is the main routing protocol used on the Internet; it designates where data will go using IP addresses. IPsec is secure because it adds encryption* and authentication to this process.
IPsec connections include the following steps:
Key exchange: Keys are necessary for encryption; a key is a string of random characters that can be used to "lock" (encrypt) and "unlock" (decrypt) messages. IPsec sets up keys with a key exchange between the connected devices, so that each device can decrypt the other device's messages.
Packet headers and trailers: All data that is sent over a network is broken down into smaller pieces called packets. Packets contain both a payload, or the actual data being sent, and headers, or information about that data so that computers receiving the packets know what to do with them. IPsec adds several headers to data packets containing authentication and encryption information. IPsec also adds trailers, which go after each packet's payload instead of before.
Authentication: IPsec provides authentication for each packet, like a stamp of authenticity on a collectible item. This ensures that packets are from a trusted source and not an attacker.
Encryption: IPsec encrypts the payloads within each packet and each packet's IP header (unless transport mode is used instead of tunnel mode — see below). This keeps data sent over IPsec secure and private.
Transmission: Encrypted IPsec packets travel across one or more networks to their destination using a transport protocol. At this stage, IPsec traffic differs from regular IP traffic in that it most often uses UDP as its transport protocol, rather than TCP. TCP, the Transmission Control Protocol, sets up dedicated connections between devices and ensures that all packets arrive. UDP, the User Datagram Protocol, does not set up these dedicated connections. IPsec uses UDP because this allows IPsec packets to get through firewalls.
Decryption: At the other end of the communication, the packets are decrypted, and applications (e.g. a browser) can now use the delivered data.
Network documentation is the practice of maintaining records of computer networks to provide data center managers information about the devices in the data center and how they are arranged.
Some data center professionals rely on outdated network topology diagrams and spreadsheets for their documentation, while Data Center Infrastructure Management (DCIM) software allows for more effective end-to-end network visualization to easily identify single points of failure and decrease troubleshooting time.
What Should Be Documented in a Network?
The Open Systems Interconnection (OSI) model presents a conceptual framework that breaks down network communication into seven distinct layers. The OSI model provides an organizational structure that is a helpful guide when diagramming and documenting the different functions and items in a network. DCIM Software helps to document Layer 1 (Physical) connectivity, port to port.
What Are the Benefits of Network Documentation?

Improving Uptime
An accurately documented network can provide quick diagnosis and impact or what-if analysis in the event of potential network issues or planned maintenance of network equipment.

Optimizing Capacity Utilization
Real-time data gives you an always-accurate picture of usage in your data center, so you can identify stranded capacity, forecast when you will run out, and make the most of your existing resources.

Improve People Productivity
You can manage devices, analyze data center business intelligence with dashboards and reports, and then make data-driven changes – all in a single system, with fewer clicks and mouse movements.

Simplifying Validation
Automatically validate the compatibility of your physical connections. DCIM prevents you from building connections across incompatible ports and when looking to deploy equipment, it will exclude cabinets without enough available, compatible connectors.
Network management is the process of administering, managing, and operating a data network, using a network management system. Modern network management systems use software and hardware to constantly collect and analyze data and push out configuration changes for improving performance, reliability, and security.
Network Management involves monitoring and controlling a network system so that it can operate properly without downtime. So, the function performed by a network management system are categorised as follows −
Fault management
Fault management is the procedure of technology used to manage the administrator who prevents faults within a networked system so that the availability of downtime is reduced by identifying, isolating and fixing any malfunctions that occur. It can support active and passive components to disavow fault.
Configuration management
It refers to the process of initially configuring a network and then adjusting it in response to changing networks requirements. This function is important because improper configuration may cause the network to work suboptimal or may not work at all.
The configuration involves the parameters at the network interface like IP address, DHCP, DNS, server address etc.
Network management
Network management is the procedure of maintaining and organizing the active and passive network elements. It will support the services to maintain network elements and network performance monitoring and management.
It recognises the fault, Investigate, Troubleshoot, Configuration Management and OS changes to fulfil all the user requirements. It allows computers in a network to communicate with each other, control networks and allow troubleshooting or performance enhancements.
Data logging and report
Data logs record all the records and interactions that pass through a specific point in a system, between keyboard and display. If any system failure appears, the administrator can go to the log and view what might have created it.
Accounting management of network resources
To keep a record of usage of network resources known as accounting management. Like to examine and to determine how to better allocate resources. One might examine the type of traffic or level of traffic at a particular port.
It can also monitor activities of users about password & user id and authentication for the usage of resources.
Performance Management
It involves monitoring network utilization, end to end response time & performance of resources at various points in a network. For example, to keep track of switched interfaces in an Ethernet.
Network Security
It refers to the process of providing security on network and network resources. It involves managing the security services on a resource by using access control, authentication, confidentiality, integrity and non-repudiation.
Network security is a broad term that covers a multitude of technologies, devices and processes. In its simplest term, it is a set of rules and configurations designed to protect the integrity, confidentiality and accessibility of computer networks and data using both software and hardware technologies. Every organization, regardless of size, industry or infrastructure, requires a degree of network security solutions in place to protect it from the ever-growing landscape of cyber threats in the wild today.
Today's network architecture is complex and is faced with a threat environment that is always changing and attackers that are always trying to find and exploit vulnerabilities. These vulnerabilities can exist in a broad number of areas, including devices, data, applications, users and locations. For this reason, there are many network security management tools and applications in use today that address individual threats and exploits and also regulatory non-compliance. When just a few minutes of downtime can cause widespread disruption and massive damage to an organization's bottom line and reputation, it is essential that these protection measures are in place.
DDoS
DDoS (distributed denial of service) attacks involve deploying sprawling networks of botnets — malware-compromised devices linked to the internet. These bombard and overwhelm enterprise servers with high volumes of fraudulent traffic. Malicious attackers may target time-sensitive data, such as that belonging to healthcare institutions, interrupting access to vital patient database records.
Man-in-the-middle Attacks
Man-in-the-middle (MITM) network attacks occur when malicious parties intercept traffic conveyed between networks and external data sources or within a network. In most cases, hackers achieve man-in-the-middle attacks via weak security protocols. These enable hackers to convey themselves as a relay or proxy account and manipulate data in real-time transactions.
Unauthorized Access
Unauthorized access refers to network attacks where malicious parties gain access to enterprise assets without seeking permission. Such incidences may occur due to weak account password protection, unencrypted networks, insider threats that abuse role privileges, and the exploitation of inactive roles with administrator rights.
Organizations should prioritize and maintain the least privilege principle to avoid the risks of privilege escalation and unauthorized access.
SQL Injection
Unmoderated user data inputs could place organizational networks at risk of SQL injection attacks. Under the network attack method, external parties manipulate forms by submitting malicious codes in place of expected data values. They compromise the network and access sensitive data such as user passwords.
There are various SQL injection types, such as examining databases to retrieve details on their version and structure and subverting logic on the application layer, disrupting its logic sequences and function.
Network users can reduce the risks of SQL injection attacks by implementing parameterized queries/prepared statements, which helps verify untrusted data inputs.
Cloud computing is a term referred to storing and accessing data over the internet. It doesn’t store any data on the hard disk of your personal computer. In cloud computing, you can access data from a remote server.
Advantages and disadvantages
Cost Savings
Cost saving is one of the biggest Cloud Computing benefits. It helps you to save substantial capital cost as it does not need any physical hardware investments. Also, you do not need trained personnel to maintain the hardware. The buying and managing of equipment is done by the cloud service provider.
Strategic edge
Cloud computing offers a competitive edge over your competitors. It is one of the best advantages of Cloud services that helps you to access the latest applications any time without spending your time and money on
High Speed
Cloud computing allows you to deploy your service quickly in fewer clicks. This faster deployment allows you to get the resources required for your system within fewer minutes.
Back-up and restore data
Once the data is stored in a Cloud, it is easier to get the back-up and recovery of that, which is otherwise very time taking process on-premise.
Automatic Software Integration
In the cloud, software integration is something that occurs automatically. Therefore, you don’t need to take additional efforts to customize and integrate your applications as per your preferences.
Reliability
Reliability is one of the biggest benefits of Cloud hosting. You can always get instantly updated about the changes.
Mobility
Employees who are working on the premises or at the remote locations can easily access all the could services. All they need is an Internet connectivity.
Unlimited storage capacity
The cloud offers almost limitless storage capacity. At any time you can quickly expand your storage capacity with very nominal monthly fees.
Collaboration
The cloud computing platform helps employees who are located in different geographies to collaborate in a highly convenient and secure manner.
Quick Deployment
Last but not least, cloud computing gives you the advantage of rapid deployment. So, when you decide to use the cloud, your entire system can be fully functional in very few minutes. Although, the amount of time taken depends on what kind of technologies are used in your business.
Disadvantages of Cloud Computing
Here, are significant challenges of using Cloud Computing:
Performance Can Vary
When you are working in a cloud environment, your application is running on the server which simultaneously provides resources to other businesses. Any greedy behavior or DDOS attack on your tenant could affect the performance of your shared resource.
Technical Issues
Cloud technology is always prone to an outage and other technical issues. Even, the best cloud service provider companies may face this type of trouble despite maintaining high standards of maintenance.
Security Threat in the Cloud
Another drawback while working with cloud computing services is security risk. Before adopting cloud technology, you should be well aware of the fact that you will be sharing all your company’s sensitive information to a third-party cloud computing service provider. Hackers might access this information.
Downtime
Downtime should also be considered while working with cloud computing. That’s because your cloud provider may face power loss, low internet connectivity, service maintenance, etc.
Internet Connectivity
Good Internet connectivity is a must in cloud computing. You can’t access cloud without an internet connection. Moreover, you don’t have any other way to gather data from the cloud.
Lower Bandwidth
Many cloud storage service providers limit bandwidth usage of their users. So, in case if your organization surpasses the given allowance, the additional charges could be significantly costly
Lacks of Support
Cloud Computing companies fail to provide proper support to the customers. Moreover, they want their user to depend on FAQs or online help, which can be a tedious job for non-technical persons.
An access control list includes a set of rules used to assign permissions or grant Organizations can use access control lists (ACL) to secure data. One of the major reasons to use access control lists is to restrict unauthorized users from accessing business-sensitive information. It can also be used to control network traffic by limiting the number of users accessing files, systems, and information. This increases network performance and helps protect business information.
Standard ACL: Standard lists are the most common type of access lists used for simple deployments. They allow you to filter only the source address of the data packet. Moreover, they are less processor intensive.
Extended ACL: Although extended lists are complex in configurations and resource-intensive, they provide a granular level of control. Using these lists, you can be more precise while filtering data packets. You can also evaluate the packets based on different factors such as source and destination IP addresses, source, and destination port, and type of protocol (ICMP, TCP, IP, UDP), and more.
Dynamic ACL: Dynamic ACLs are often known as Lock and Key, and they can be used for specific attributes and timeframes. They rely on extended ACLs, authentication, and Telnet for their functionality.
Reflexive ACL: Reflexive ACLs are also known as IP session ACLs. They filter IP traffic based on upper-layer session information. These ACLs can only be used to permit IP traffic generated within your network and deny the IP traffic generated from an external or unknown network.
Time-based ACL: Time-based ACLs are similar to extended ACLs. However, they can be implemented by creating specific times of the day and week.
How does the ACL work?
A filesystem ACL is a table that informs a computer operating system of the access privileges a user has to a system object, including a single file or a file directory. Each object has a security property that connects it to its access control list. The list has an entry for every user with access rights to the system.
Typical privileges include the right to read a single file (or all the files) in a directory, to execute the file, or to write to the file or files. Operating systems that use an ACL include, for example, Microsoft Windows NT/2000, Novell’s Netware, Digital’s OpenVMS, and UNIX-based systems.
When a user requests an object in an ACL-based security model, the operating system studies the ACL for a relevant entry and sees whether the requested operation is permissible.
Networking ACLs are installed in routers or switches, where they act as traffic filters. Each networking ACL contains predefined rules that control which packets or routing updates are allowed or denied access to a network.
Routers and switches with ACLs work like packet filters that transfer or deny packets based on filtering criteria. As a Layer 3 device, a packet-filtering router uses rules to see if traffic should be permitted or denied access. It decides this based on source and destination IP addresses, destination port and source port, and the official procedure of the packet.
Describe basic OSPF features and characteristics.
Ans: Open Shortest Path-First abbreviated as OSPF is simply a routing protocol for Internet Protocol (IP) networks and is based on the Shortest Path First (SPF) algorithm. It is a link-state routing protocol that was developed as an alternative to distance vector routing protocol (RIP). OSPF is an intradomain protocol I.e., used within an area or a network. Herein, each router contains the information of every domain, and based on that very information, determines the shortest path.
Feature and characteristics of OSPF are as listed below:
- It provides routing information to the IP section of the TCP/IP protocol suite, the most used alternative to RIP.
- It is based on SPF (Shortest Path First) algorithm.
- OSPF bases link cost on bandwidth to determine the best route.
- It sends updates to tables only, instead of entire tables, to routers.
- It involves less network traffic.
- It supports unlimited hop count.
- It is a classless protocol therefore, it supports VLSM (Variable Length Subnet Mask) and CIDR (Classless Inter-Domain Routing).
Explain how single-area OSPF operates. Describe the OSPF packet types used in single-area OSPF.
Ans: OSPF (Open Shortest-Path First) refers to a routing protocol belonging to the group of link-state routing protocols. It is classified among the best dynamic protocols that exist in networks today. Using Dijkstra Algorithm, OSPF calculates the shortest path to every router.
We can implement OSPF in two different ways, I.e., Single-Area OSPF and Multi-Area OSPF. Single Area OSPF is also termed as Area 0. It is the backbone area for OSPF which links all other smaller areas within the hierarchy. Herein, all routers are contained in one area and are preferably used in smaller networks where only a few routers are working and the web of router links is not complex, and paths to individual destinations are easy. OSPF supports hierarchical routing using areas which make OSPF more efficient and scalable.
To enable single-area OSPF, firstly we are required to enable OSPF. Enabling OSPF is not enough to activate it. The OSPF process needs to know the networks that are going to be advertised and the area they reside in. Therefore, the following command is needed to make OSPF operational: -Router(config-router)# networkaddress_wildcard-mask_area_area-number
Herein, the network command is used to identify the interfaces on the router that are going to participate in the OSPF process. Adjacencies will be created with these interfaces and the LSAs will be received and transmitted on these interfaces. The wildcard mask parameter here needs to be defined for accurately identifying the necessary interfaces. In wildcard mask, 0 bit indicates a “must” and 1 bit indicates an “any”. And, the area-number specifies the area to be associated with the specific address and consequently the interfaces to be grouped within that area. By default, area 0 is used if more than one area is to be created in a network, area 0 is the first one that needs to be defined.
OSPF packet types used in single-area OSPF are briefly described below:
I. Hello packet – Hello packet is responsible for discovering and creating neighborhood relationships and checking the network’s reachability. Simply it is used when the connection between routers needs to be established.
II. Database Description (DBD) – Once the two-way communication is established, database description packets are sent using the exchange database protocol. Furthermore, it checks for database synchronization between routers.
III. Link State Request (LSU) – Link state request is sent by router to obtain the information of a specified router.
IV. Link State Update (LSU) - Link state update if further used by router to advertise the state of its links.
V. Link State Acknowledgement (LSAck) - Finally, LSAck is responsible for sending acknowledgement packets to each router, ensuring reliability factor.
Describe common network attacks & also describe the best practices for protecting a network.
Ans: A network attack is an attempt to gain unauthorized access to an organization network with the objective of stealing data or perform other malicious activity.
There are two main types of network attacks:
• Active: Attackers not only gain unauthorized access but also modify data, either deleting, encrypting, or otherwise harming it.
• Passive: Attackers gain access to a network and can monitor or steal sensitive information, but without making any change to the data, leaving it intact.
The common network attacks are as follows: Computer Virus, Malware attacks, DOS attacks, Brute force attacks & phishing etc.
The best practices for protecting a network are as follows:
1. Create strong passwords and change regularly: Creating a strong password for several types of network devices such as: Router, Firewall, Switch, etc. to prevent attack. Don’t use easy passwords to remember such as: birthdate, Iloveyou123, mobile number. Use strong password by using combine letter numbers, special characters and minimum 10 character in total. For example: *Hustle@1234
2. Don’t click unwanted email or message: Sometime you will receive an unwanted email from unknown person with attachment file, that can be a virus or malware which can harmful our system or network. So, before clicking that file we must beware or sometime deleting that email will be better.
3. Use Antivirus Software: Antivirus is a program that helps to protect our system, network and IT system from viruses, malware, worms, and other unwanted threats. It scans our entire system and scan files from the internet. There are some popular anti-viruses like: Avast, panda, Quick scan and many more.
4. Use Firewall: We can use firewall to monitor the incoming or outcoming network traffic. The benefits of firewall are: protecting from hacking, stops virus & malware and promote privacy.
5. Use virtual Private Networks (VPN): The main purpose of using VPN is to hide your personal online data from others. It helps to hide our IP address, browsing activity and online data from the network. If we live in Kathmandu but by using VPN, we can change our device's location to another place like Birganj, Palpa etc. which can be extremely useful.
Describe malware types. Explain how TCP and UDP vulnerabilities are exploited by threat actors.
Ans: Malware abbreviation of malicious software refers to any intrusive files or software intended to infect, explore, steal, or conduct any harmful activities in our system. Cybercriminals use it against us to exploit and harm our system for stealing our necessary data and information. Common malware types include; Viruses, Worms, Ransomware, Bots, Trojan, Spyware, Spam & Phishing, etc. Some common malware types are briefly discussed below:
• Worms – Worms are spread via software vulnerabilities or phishing attacks. Once a worm is installed into your computer memory, it starts to infect the entire system and, in some cases, the overall network too. Depending on the types and your security measures, they can do some serious damage which are;
I) Modify and delete files
II) Inject malicious software onto computers.
III) Steal your data
IV) Install a convenient backdoor for hackers
• Viruses – Viruses unlike worms require an already infected active operating system to function. It usually spreads via infected websites, email attachments, file sharing, etc. Once your system or program is activated, the virus is able to replicate itself and spread throughout your system. So, accessing any files, email, etc. from untrusted sources should be ignored.
• Trojans: Trojans is a program or file that trick user into downloading and installing them as it looks trustworthy. Once you install, they take control of the system and inject the system and work as spies of your system making it an easier approach for hackers.
• Ransomware – It is one of the most used malwares. A ransom-ware is malicious software that uses encryption to disable a victim’s access to its own data and demands a ransom, usually in a cryptocurrency in return to decrypt the encrypted data.
Network applications use TCP or UDP ports. Threat actors conduct port scans of target devices to discover which services they offer. An outbound ACL filters packets after being routed, regardless of the inbound interface. Incoming packets are routed to the outbound interface and then they are processed through the outbound ACL.
Explain how ACLs filter traffic. Compare standard and extended IPv4 ACLs.
Ans: When we send or receive data or information, it may contain files that are vulnerable to many unwanted and dangerous traffic. So, such traffic must be monitored in order to prevent loss of any information. And Access Controls Lists (ACL) are responsible for monitoring, allowing, or blocking such harmful traffic right at the router's interface. Thus, ACL is a traffic filter that works based on certain rules and commands which enables it to either restrict or allow data packets to transfer from source to destination.
An inbound ACL filter packets before they are routed to the outbound interface. Inbound ACLs are significantly used to filter packets when the network attached to an inbound interface is the only source of packets that needs to be examined. In ACL, when a network traffic passes through an interface, the router compares the information within the packet against each ACE (Access Controlled Entries), in sequential order to determine if the packet matches one of the ACEs. This process is called packet filtering. And in this way ACLs filter traffic.
On the basis of purpose ACLs are broadly categorized into many types. Among them the major two are: Standard ACL and Extended ACL. Differences between Standard and Extended IPv4 ACLs are as listed below;
Explain how to create ACLs.
Ans: Access Control List (ACL) is a traffic filter that works based on certain rules and commands so as to restrict or allow data packets to transfer from source to destination. For proper implementation of ACL, we should primarily understand ingress and egress traffic in the router. When setting rules for an ACL, all traffic flow are based on the point of view of the router’s interface. There is a limit in the number of ACLs that can be applied on a router interface. For example- a dual stacked (i.e., IPv4 and IPv6) router interface. A router interface can have:
- One outbound IPv4 ACL
-One inbound IPv4 ACL
- One outbound IPv6 ACL
For functioning of ACL in proper way, firstly apply it to a routers interface. It is done so as to make our process easier and less time-consuming as all routing and forwarding decisions are made from the router’s hardware. Further, when we create an ACL entry, we should follow a particular pattern wherein source address goes first followed by destination address. The incoming flow is the source of all hosts or network and outgoing is the destination of all hosts and network hence source address comes beforehand. For e.g., When we configure extended ACL for IP on a Cisco router, to create deny/permit rule, we must define source first then destination. Syntax of the same is;
IP
access-list <access-list no.>
{deny/permit} protocol-source_source-wildcard-mask_destination_destination-wildcard-mask
Hence, following the abovementioned factors we can create ACLs.
Describe the advantages and disadvantages of NAT.
Ans: Network Address Translation (NAT) is a process in which one or more local IP address is translated into one or more Global IP address and vice versa in order to provide Internet access to the local hosts. Also, it does the translation of port numbers i.e. masks the port number of the host with another port number, in the packet that will be routed to the destination.
The Advantages of NAT are:
• The main advantage of NAT (Network Address Translation) is that it can prevent the depletion of IPv4 addresses.
• NAT (Network Address Translation) can provide an additional layer of security by making the original source and destination addresses hidden.
• NAT (Network Address Translation) provides increased flexibility when connecting to the public Internet.
.NAT (Network Address Translation) allows to use your own private IPv4 addressing system and prevent the internal address changes if you change the service provider.
The Disadvantages of NAT are:
• NAT (Network Address Translation) is a processor and memory resource consuming technology, since NAT (Network Address Translation) need to translate IPv4 addresses for all incoming and outgoing IPv4 datagrams and to keep the translation details in memory.
• NAT (Network Address Translation) may cause delay in IPv4 communication.
• NAT (Network Address Translation) cause loss of end-device to end-device IP traceability.
Some technologies and network applications will not function as expected in a NAT (Network Address Translation) configured network.
Explain how the IPsec framework is used to secure network traffic.
Ans: Internet Protocol Security (IPsec) is an IETF standard (RFC 2401-2412) that defines how a VPN can be secured across IP networks. IPsec protects and authenticates IP packets between source and destination. It can also define the encrypted, decrypted and authenticated packets.
Using IPsec framework, IPsec provides these essential security functions:
1. Confidentiality- IPsec uses encryption algorithms to prevent cybercriminals from reading the packet contents.
2. Integrity- IPsec uses hashing algorithm to ensure that packets have not been altered between source and destinations. It ensures the originality of our transferred information.
3. Origin authentication- IPsec uses the Internet Key Exchange (IKE) protocol to authentic source and destination. Methods of authentication include using pre-shared keys, digital certificates, or RSA certificates. Diffie-Hellman-Secure Key exchange typically uses various groups of DH algorithm.
IPsec is not bound to any specific rules for secure communications. This flexibility of the framework allows IPsec to easily integrate new security technologies without updating the existing IPsec standards. IPsec encrypts data packets sent over the IPv4 and IPv6 networks. IPsec protocols use a format called Request for Commands (RFC) to develop the requirements for the network security standard, it makes use of tunneling. The data packets that we define as sensitive or interesting are sent through the tunnel securely. By defining the characteristics of tunnel, the security protection measures of sensitive packets are defined.
Describe different types of VPNs with their benefits.
Ans: A virtual private network better known as a VPN, gives you online privacy and anonymity by creating a private network from a public internet connection. VPNs mask your internet protocol (IP) address so your online actions are virtually untraceable. Most important, VPN services establish secure and encrypted connections to provide greater privacy than even a secure Wi-Fi hotspot.
The different types of VPNs are as follows:
A) Remote access VPNs.
B) Personal VPNs services.
C) Mobile VPNs.
D) Site-to-site VPNs.
Remote access VPNs: A remote access VPN lets you use the internet to connect to a private network, such as your company’s office network. The internet is an untrusted link in communication. VPN encryption is used to keep the data private and secure as it travels to and from the private network. Remote access VPNs are also sometimes called client-based VPNs or client-to-server VPNs.
Personal access VPNs: A personal VPN services connects to you to a VPN server, which then acts as a middleman between your devices and the online services you want to access. The personal VPN encrypts your connection, hides your identity online and lets you spoof your geographical location.
Mobile VPNs: A mobile VPN is a better potion than a remote access VPN if the user is unlikely to have a stable connection on the same network for the entire session. A mobile VPN can be used with any devices and any connection, it doesn’t have to be a mobile phone on a mobile network.
Site-to-Site VPNs: Whereas a remote access VPN is designed to let designed to let individual users connect to a network and its resources, a site-to-site VPN joins together two networks on different sites. If a company had two offices on the east coast and west coast, for example: a site-to-site VPN could be used to combine them into a single network. Site-to-site VPNs are also sometimes known as network-based VPNs.
Describe the different QoS models. Describe the different QoS models.
Ans: Quality of Service abbreviated as QoS refers to any technology that manages data traffic to reduce packet loss, latency, etc.
There are three different QoS models which are listed and briefly described below:
1) Best-effort model
2) Integrated Services (IntServ)
3) Differentiated services (DiffServ)
Best-effort model: The best-effort model treats all network packets in the same way, so an emergency voice message is treated the same way that a digital photograph attached to an email is treated.
Integrated services (IntServ): IntServ delivers the end-to-end QoS that real-time applications require. It explicitly manages network resources to provide QoS to individual flows or streams, sometimes called microflows. It uses resource reservation and admission control mechanisms as building blocks to establish and maintain QoS. It uses a connection-oriented approach. Each individual communication must explicitly specify its traffic descriptor and requested resources to the network. The edge router performs admission control to ensure that available resources are sufficient in the network.
Differentiated services (DiffServ): The differentiated services (DiffServ) QoS model specifies a simple and scalable mechanism for classifying and managing network traffic. It is not an end-to-end QoS strategy because it cannot enforce end-to-end guarantees. Hosts forward traffic to a router which classifies the flows into aggregates (classes) and provides the appropriate QoS policy for the classes. Enforces and applies QoS mechanisms on a hop-by-hop basis, uniformly applying global meaning to each traffic class to provide both flexibility and scalability.
Explain how network transmission characteristics impact quality.
Ans: QoS (Quality of Service) is a very crucial factor of any system nowadays. Customer satisfaction is a major objective of any system and QoS must be ensured to fulfill that. New applications, such as voice and live transmissions, create higher expectations for quality among users.
Network Transmission Quality is important for network communications. When we have a file that needs to be transmitted and the traffic volume is greater than the actual what could be transported, then we must have a kind of mechanism where our data is hold for certain time and later released section by section to interface based on the memory and hardware’s resources which are available in that particular device. If traffic volume is greater congestion occurs. Congestion basically is a condition when multiple communication lines aggregate onto a single device such as router, and then much of that data is placed on just a few outbound interfaces, or onto a slower interface. It can also occur when large data packets prevent smaller data packets from being transmitted in a timely manner.
The volume of traffic being greater i.e., congestion enables device queue that holds the packets in memory until resources become available to transmit them. Queueing packets will mainly result in
delays as when we have to hold our packets until the previous one has been processed. And if the number of packets in queue (hold) increases, then the memory within the device fills up and packets are dropped. This leads to inefficiency in our system also, the quality of service is degraded.
Explain different types of Device Discovery Protocol with configuration syntax.
Ans: Discovery protocol or service discovery protocol simply refers to network protocols which allow automatic detection of devices and services offered by these devices on a computer network. We can also consider it as an action of finding a service provider for a requested service. Three primary Discovery Protocol includes;
1. Cisco Discovery Protocol (CDP)
2. LLDP (Link Layer Discovery Protocol)
3. SNMP (Simple Network Management Protocol)
1) Cisco Discovery Protocol
Cisco Discovery Protocol (CDP) is Layer-2 proprietary protocol which is basically used to discover and share information about network-connected Cisco equipment. CDP cannot be operated on any other Windows. This protocol collects information about Cisco neighbor devices and the Cisco devices share their information by sending CDP announcements after every 60 secs. The hold down time is 180 secs. If no announcements are received from a device before the timer expires, the device’s information is discarded. Basic commands of CDP are;
- show cdp neighbors
- show cdp neighbor's details.
CDP is a powerful network monitoring and troubleshooting tool. It enables us to access a summary of protocol and address information about Cisco devices that are directly connected.
2) Link Layer Discovery Protocol
Link Layer Data Protocol is a vector-neutral, layer-2 discovery protocol. It is used by network devices to share information about their identities and functionality with other network elements. LLDP defines a standard method for Ethernet network devices to advertise information about themselves to other nodes on the network and store the information they discover. It allows devices to send and receive LLDP data units to and from neighbors. Receiving device stores information in a MIB (Management Information Base) which can be accessed using SNMP protocol. Basic commands of LLDP are;
- #show lldp
- #show lldp entry </entry-name
- #clear lldp table
- #clear lldp counter
3) Simple Network Management Protocol
Simple Network Management Protocol (SNMP) is an application layer protocol that provides a message format for agents on a variety of devices to communicate with network management situations (NMSs). The NMS periodically queries polls SNMP agent on a device to gather and analyze statics via GET messages. End devices running SNMP agents would send SNMP trap to NMS if problem occurs.
Explain how SNMP operates. Describe syslog operation.
Ans: Simple Network Management Protocol (SNMP) is an application layer protocol that provides a message format for agents on a variety of devices to communicate with network management situations (NMSs). All SNMP messages are transported via UDP. The SNMP agent receives request on UDP port 161. The manager may send a request from any available source to port 161 to the agent.
SNMP works by sending messages called Protocol Data Units (PDUs), to devices within your network that “speak” SNMP. These messages are called SNMP Get requests. Using these requests, network administrations can task virtually any data values they specify.
Talking about how SNMP operates, the following operations are performed sequentially:
Syslog refers to system logging protocol. On Cisco network device, the syslog protocol starts by sending system messages and debugging output to a local logging process that is internal to the device. Logging process manages these messages and debug output to a local logging process that is internal to the device. The logging process manages these messages and output is based on device configurations. For e.g., syslog messages may be sent across the network to an external syslog server. These messages can be retrieved without any need to access the actual device. Log messages and output stored on the external server can be pulled into various reports for easier reading. Alternatively, syslog messages may be sent to an internal buffer. Messages sent to an internal buffer are only viewable through the CLI of the device.
Finally, the network administrator may specify that only certain types of system messages be sent to various destinations. For example: the device may be configured to forward all system messages to an external syslog server. However, the debug-level messages are forwarded to the internal buffer and are only accessible by the administrator from the CLI.
Explain considerations for designing a scalable network.
Ans: Scalable network in terms of IT refers to any network that can continue to grow in future without losing its authenticity, reliability, and availability.
Any well-designed network should have a scalable factor in it. This means the chosen topology should be able to accommodate projected growth. The network designer should work considering the scalable factor of the decision. A small, medium, or large network should be available to work efficiently and easily to further assure the scalability factor. Major considerations for designing a scalable network are as listed below:
- Use expandable, modular equipment, or clustered devices that can be easily upgraded to increase capabilities. Device modules can be added to the existing equipment to support new features and devices without requiring major equipment upgrades.
- Design a hierarchical network to include modules that can be added, upgraded, and modified as necessary without affecting the design of the other functional areas of the network.
- Create an IPv4 and IPv6 address strategy that is hierarchical. Careful address planning eliminates the need to re-address the network to support additional users and services.
- Choose routers or multilayer switches to limit broadcasts and filter other undesirable traffic from the network. Use layer 3 devices to filter and reduce traffic to the network core.
Since, scalable network is quite a crucial factor for any organization, aforementioned points are some of the things to be considered while designing our network.
Explain the importance of cloud computing. Describe software-defined networking.
Ans: Cloud computing is the delivery of computing services—including servers, storage, databases, networking, software, analytics, and intelligence—over the Internet (the cloud) to offer faster innovation, flexible resources, and economies of scale.
Importance of cloud computing includes;
• Scalability: Cloud computing allows you to use as many or as few resources as you need. Therefore, depending on your business needs or projected traffic to your business you can choose to increase or decrease your investment in IT infrastructure.
• Saving Costs: Cloud computing helps businesses to reduce costs in various ways. Companies only pay for the resources they use, making this process a more economical option than having to buy and manage their own resources. Cloud computing also results in considerable savings in Capital Expenditure and Operating Expenditure because companies do not have to invest in expensive hardware, storage devices, software, etc.
• Disaster Recovery: With all data stored in the ‘cloud’ backup and recovery of data and applications is quicker and more reliable. This applies to all sizes of organizations and volumes of data. 20% of cloud users claim disaster recovery in four hours or less as opposed to only 9% of non-cloud users.
• Security: It is the duty and responsibility of the cloud service providers to carefully monitor security. Compare this against an in-house I.T. department, for example, which is tasked with so many internal processes to manage; security is just one of the many items on the list.
• Flexibility: When using cloud computing the number of options is vast. Depending on the size of the organization, business needs, workloads, etc., companies can choose cloud infrastructure and services accordingly.
Software-Defined Networking (SDN) is a network architecture approach that enables the network to be intelligently and centrally controlled, or ‘programmed,’ using software applications. This helps operators manage the entire network consistently and holistically, regardless of the underlying network technology.
Explain the importance of virtualization. Describe the virtualization of network devices and softwares.
Ans: Virtualization is the process of running a virtual instance of a computer system in a layer separate from the actual hardware. Virtualization can increase IT agility, flexibility and scalability while creating significant cost savings. Greater workload mobility, increased performance and availability of resources, automated operations – they’re all benefits of virtualization that make IT simpler to manage and less costly to own and operate.
The importance of Virtualization are as follows:
Easier IT management:
The benefits of virtualization technology are that the IT representatives saved a large part of the provisioning work and grueling maintenance that actual servers require. A new VMWare white paper noted. Considering that routine tasks like launching new applications and adding new server workloads represent at any rate half of representatives’ time.
Speedy Recovery Time:
The benefits of virtualization in disaster recovery are to consider quicker recuperation of IT resources that accommodate improved business revenue and continuity. The more seasoned frameworks are unequipped for recuperating inside a couple of hours, and, organizations experience any longer downtime, which brings about income misfortune.
Better Scalability:
The other benefits of virtualization are that the virtualized conditions are intended to be versatile, which considers greater adaptability regarding organization development. Rather than buying extra infrastructure components, new upgrades and applications can be executed with virtualization without much of a stretch.
More agile business processes:
Another benefit of virtualization is that the business world changes quickly, and organizations should have the option to react in a similar manner. Rather than customary organization plans, which required making arrangements for hardware installation and purchases, virtual foundation permits organizations to scale quickly, including new virtual servers' request. Moreover, it’s simpler to change how virtual resources are allotted, enabling organizations to move methodologies in a hurry.
Move to be more green-friendly:
At the point when you can eliminate the number of actual servers you are utilizing, it will lead to a decrease in the measure of power being devoured. These two green benefits of virtualization are that it diminishes the data center's carbon impression and lessens costs for the business. That money can be reinvested somewhere else.
Network virtualization means virtual network components can mimic real-world physical hardware functions. Now we can have things like a virtual router inside a router, a virtual switch inside a switch, virtual firewalls inside a firewall and all those network devices can be virtualized inside a server/PC. We can utilize network resources efficiently by using virtual networks.
Describe the purpose of WANs. Briefly explain the types of WANs topology designs.
Ans: A wide area network (also known as WAN), is a large network of information that is not tied to an individual location. WANs can facilitate communication, the sharing of information and much more between devices from around the world through a WAN provider. It consists of high border geographical areas. It provides internet, mail, and e-commerce services. It can provide real-time communication with each device.
The main purpose of WANs is if there is no WAN connection, the organization will be isolated in a restricted area or a specific geographic area. The wide area network will allow organizations to work in their buildings, but cannot extend to outside areas (different cities or even different countries). As organizations grow and internationalize, WAN allows them to communicate between branches, share information, and stay connected. However, the wide area network also provides basic services to the public. University students may rely on WAN to access library databases or university research. Every day, people rely on WAN for communication, banking, shopping, etc. WANs can be vital for international businesses, but they are also essential for everyday use, as the internet is considered the largest WAN in the world.
The types of WANs are as follows:
Point-to-Point WAN Topology: Point-to-Point WAN topology is the topology that connects one site to the other like they are connected directly. This type of topology is also called Leased Lines. They are leased from a Service Provider based on required bandwidth and the distance between the two sites. They are not a shared solution. So, if we compare Point-to-Point connections with the other WAN solutions, they are an expensive solution.
Hub and Spoke WAN Topology: Hub and Spoke Topology is the topology that is used to connect multiple sites. In this type of WAN topology, there are two roles as its name implies, Hub and Spoke. Hub is the central device at one site that is connected to all the other devices. The Spokes are only connected to the Hub. There is not a direct connection between Spokes. Hub and Spoke WAN Topology is less expensive if you compare this design with a Point to Point one. Because, there is no need to connect each site one by one to other sites.
Full Mesh WAN Topology: Full Mesh WAN Topology is the topology that each site is connected to the other sites one by one. This topology needs more resources and is expensive. Besides, it needs an extra effort because of the number of connections. The connection number that we need for a Full Mesh Topology is calculated with the formula below:
N x (N-1) / 2
Dual-Homed WAN Topology: Dual-Homed WAN Topology is a very good solution for better performance, load balancing and redundancy. But it has a disadvantage about the cost. It is an expensive solution. In Dual-Homed Topology, a site is connected to another two central sites.
Explain the purpose and function of NAT. Explain the operation of different types of NAT.
Ans: NAT stands for network address translation. It is a way to map multiple local private addresses to a public one before transferring the information. Organizations that want multiple devices to employ a single IP address use NAT, as do most home routers. Network address translation allows IP address conservation. Organizations using NAT could use hundreds, or even thousands of private addresses, while only using a single public IP address. Larger organizations may still use more public IP addresses for public servers, while keeping all the internal workstations and servers configured with private NAT addresses.
The functions of NAT are as follows:
Address translation for data transfer: When the packets are transmitted from a local host to another host in another network, then the packets are moved from local network to global network. Then, the NAT process of the border router converts the local IP address of the transmitted packet to a global IP address. When that packet moves from global network to local network, then again, the global IP is converted to local IP and the packet reaches the local host of that network.
Security in IP addresses: NAT provides privacy of the device IP addresses by keeping them hidden when traffic flows through the network. Using the IP masquerading process NAT hides the device IP addresses.
Eliminates address renumbering: It eliminates the address renumbering when a network evolves.
Firewall security: It has important applications in firewall security, by conserving the number of public addresses within an organization along with strict control over accessing resources at both sides of the firewall.
